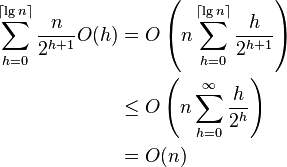I'm unsure how to explain why building a heap with the entire list/array given in advance achieves O(n) vs successive insert which is worst with O(nlgn).

Welcome to the Java Programming Forums
The professional, friendly Java community. 21,500 members and growing!
The Java Programming Forums are a community of Java programmers from all around the World. Our members have a wide range of skills and they all have one thing in common: A passion to learn and code Java. We invite beginner Java programmers right through to Java professionals to post here and share your knowledge. Become a part of the community, help others, expand your knowledge of Java and enjoy talking with like minded people. Registration is quick and best of all free. We look forward to meeting you.
>> REGISTER NOW TO START POSTING
Members have full access to the forums. Advertisements are removed for registered users.
 LinkBack URL
LinkBack URL About LinkBacks
About LinkBacks


I'm unsure how to explain why building a heap with the entire list/array given in advance achieves O(n) vs successive insert which is worst with O(nlgn).

Wikipedia - Binary Heap
Building a heap with all the information available involves 2 steps:
1. Dump all the elements into the structure (O(n)).
2. Satisfy the heap property of each sub-tree, starting with the bottom leaves.
Let's consider a max-heap, though the logic is the same for a min-heap.
The height h of the heap is guaranteed to be O(log(n)) since heaps are balanced binary trees.
At the most basic level, you're working with a structure like this:
b a c
a is guaranteed to be the max of the left sub-tree.
c is guaranteed to be the max of the right sub-tree.
There are 3 things which could happen:
1. a and b swap.
2. b and c swap.
3. no swaps.
Case 3 involves the least work so we'll ignore it.
Case 1 and 2 are basically the same, so let's analyze case 1.
Since we swapped a and b, we need to check if b needs to percolate down or not.
Now we repeat the same process over again:
[a] b d e
Again, we have 3 choices.
1. b and d swap.
2. b and e swap.
3. no swaps.
And again, case 3 is uninteresting and 1/2 are basically identical.
As you can see, it's possible for b to keep percolating down-wards. However, it can never percolate back up in this process (since its parent is always guaranteed to be larger than it).
b can at most percolate down h-x levels (where x was the initial level of b), though for all intensive purposes this is O(h).
We next move over to the sibling sub-tree of this tree and re-run the same O(h) percolation down.
At each level j, we have n / 2 ^ (j+1) sub-trees we have to repeat this process for.
The rest is just adding up all of the worst-case scenarios. As I can't really display the equations as nicely as wikipedia does, so I'll just post their equations:
Hopefully that was helpful, it's been a long time since I've worked this directly with heaps (it's also really late and the sleep deprivation does not help the thinking).
If I wanted a max-heap, then if my array is is descending order, then the max-heap is already built so I understand why that is faster than performing build heap on an array with ascending order items (worst case) b/c the most swaps to maintain the max-heap. I am timing my results but I am unsure why when given a randomized entries for an array, it takes longer to build a max heap than compared with building a max heap with ascending ordered items.. The example I used was:
for the randomized data of n = 11 (n is input size of 11 entries)
for array given:[6,9,7,8,3,18,4,11,2,10,5] and total of 6 swaps to build a max-heap
(VS)
for the ascending data of n = 11
for array given: [2,3,4,5,6,7,8,9,10,11,18] and total of 8 swaps to build a max-heap.
so as expected, with an ascending data in an array (given in advance), both hae O(n) upper bounds run time, but I am unsure why randomized data takes longer, what could be the constant factor(s) causing this...
(VS)
for descending data of n = 11
for array given: [18,11,10,9,8,7,6,5,4,3,2] and total of 0 swaps to build a max-heap b/c already a max-heap to begin with (so I expected this to be faster than with ascending entries, but not sure why randomized data takes longer than ascending data though...) ANy help appreciated
How are you timing your results?I am timing my results
Micro benchmarking in Java is a very tricky subject, there can be huge variances to your times even when you try benchmarking the exact same code.
Also, benchmarking really small datasets is very inaccurate because every small effect is amplified. Try using a large enough dataset so each time sample is at least several milliseconds.
But in general, is my logic correct where building a heap (bottom up) for descending data faster > build heap via ascending data > build heap via random data.
I used 1 million items for random values in an array and also 1 million items for ascending items in an array and I got:
using 1 million descending data to build max-heap ~ 10ms
using 1 million ascending data to build max-heap ~ 18ms
using 1 million random data to build max-heap ~ 24ms
I repeated experiement 10 times and took average time, appreciate any suggestions because buildinga max-heap with random data should be BETTer than bulding a max-heap via ascending data, so that is where I'm stuck...
Again, I'd appreciate any suggestions.
And then when I actually perform heap sor, I get:
using 1 million descending data to heap sort ~ 279ms
using 1 million ascending data to heap sort ~267ms
using 1 million random data to heap sort ~ 370ms
I'm unsure why random data should take longer.
Hmm...
I can't see any inherent reason why this is the case, though I have verified that the results appear to be valid (ran about 256 times, took the median over a wide variety of dataset sizes).
I suspect this is due to the low-level hardware stuff, perhaps something like cache/memory coherency or some other feature of new CPU's.
edit:
Tried it in C++ as well to see if it was Java-specific, got the roughly the same results, though the difference is smaller. Backs the idea that this is somehow related to low-level hardware, though there may be some code in the JVM which is making this difference more prevalent.
**But in general, is my logic correct where building a heap (bottom up) for descending data faster > build heap via ascending data > build heap via random data. The reason it makes sense to use max-heap is so that the final array (using in-place) is in sorted order (in ascending order) and so we need the heap to be in descending order each time to maintain the heap.
I need to write up a report, it is probably the constant factors like the JVM as you mentioned. So just curious, you used bottom up build heap (so starting from the lowest internal node located at index flooor(n/2) and then working back towards the root, right? Appreciate anything constructive
You mean descending > random > ascending based purely on number of swaps required, though as we've noticed that there is something else going on which is mucking up the timings.descending data faster > build heap via ascending data > build heap via random data
Your logic about why descending is fastest is correct (it's already a valid heap so things go really fast).
Yes, I work bottom-up.

 Reply With Quote
Reply With Quote